本間峰一 様、
「コンサルの最初の手順として最大値(異常滞留)の発生原因を分析してつぶしておく必要があるという話をしています。業務改善コンサルなら当たり前のアプローチだと思います」
“異常値の発生原因をつぶす”は最もよく使われる基本的なアプローチだということについては同感です。広く普及し、最もお馴染みな問題解決手順であることも承知しております。
そのためか、どんな問題でもこのアプローチが使える、と思われているようです。
実際は、“異常値の発生原因をつぶす”というアプローチが有効である場合と役に立たない場合があります。役に立たない場合は、役に立たないばかりではなく、無益な資源の浪費、無用な混乱を引き起こすなど、弊害の方が大きくなります。
“異常値の発生原因をつぶす”というアプローチが有効な事例はたくさんありますが、ここで議論している生産リードタイムの中の製造時間(処理時間、作業時間、、)の改善(短縮、バラツキ縮小、、など)を例に取り上げてみます。
例として、直列5工程のラインを例にします。単純にどの工程も平均処理時間は5時間(単位は、分でも、日でもなんでもかまいません)、バラツキは正規分布、標準偏差は1時間とします。投入から完成までの所要時間は、
平均;5+5+5+5+5=25時間
標準偏差;√12 +12+12+12+12=2.24時間
例えば、30時間以上を異常とすると、30時間以上かかるワークの割合は
1-NORM.DIST(30,25,2.24,TRUE)=0.012802761
となり、1.3%ほどの確率であることがわかります。1.3%は、異常ではないのに異常と判断する確率です。
何らかの識別でサンプリングして、それが異常かどうかをみるときは、分布の重なり具合を見て(計算して)判断します。このあたりの話は、品質管理では必ず出てくる基礎的な部分です。
処理時間は分散の加法性が成り立ち、また、生産ラインの負荷状態に依存しません。
“異常値の発生原因をつぶす”というアプローチが成立する条件は、対象とする値の確率分布が分かっている(推定できる、近似できる)ことです。多くの場合、正規分布で近似できますので、日常では、そんなことをいちいち考えないで“異常値”対策を行っても大きな間違いは起きないでしょう。
では、待ち時間はこの条件、つまり、待ち時間の確率分布は分かっているのか? ですが、結論からいえば、分かっていないんです。
待ち行列の分布はどういうものか、分散を求める方法はあるのか、、など待ち行列理論の本やWEBで検索してみました。到着時間や処理時間の確率分布を限定して、待ち時間の平均を求める計算式はあります。しかし分散や標準偏差を求める実用的な式はありません。それに関する論文はあるようですが、多くは、大学生の卒業研究などで、実用になるようなものはないようです。
待ち時間のバラツキがどのようになるか、数式モデルがありませんのでわかりませんが、シミュレーションで概要を知ることができます。直列5工程の生産ラインで待ち時間がどうなるか、簡単にシミュレーションしてみます。
その前に待ち時間はどのような要素で決まるか、確認しておきます。工程が1つの場合の待ち時間の平均は次の式で求められます。分布形状を特定するとめんどくさくなりますので、分布を一般化した近似式を使います。
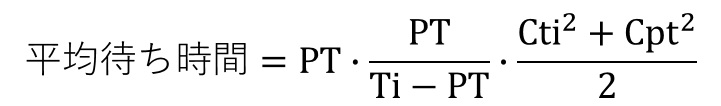
PT;工程処理時間平均
Ti;工程への到着時間間隔平均
Cpt;PTの変動係数
Cti;Tiの変動係数
平均待ち時間はPTに比例します。
式では気か付きにくいのですが、稼働率が大きく影響します。稼働率;ρは次の式で計算されます。
稼働率;ρ=PT÷Ti
ρを使っ平均待ち時間を求める式は次のようになります。
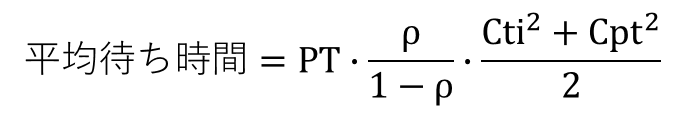
平均待ち時間を決める因子は
PT(処理時間)、ρ(稼働率)、Cpt(処理時間の変動係数)、Cpt(到着時間間隔の変動係数)
ということになります。
では、前述の直列5工程でのシミュレーション結果を見ていきます。条件は以下の通りです。
投入期間間隔;指数分布(変動係数1)
各工程の処理時間はすべて平均5時間、変動係数0.5
稼働率を50%、60%、70%、80%、90%、95%、98%と換えたときの待ち時間のシミュレーション結果を下図に示します。
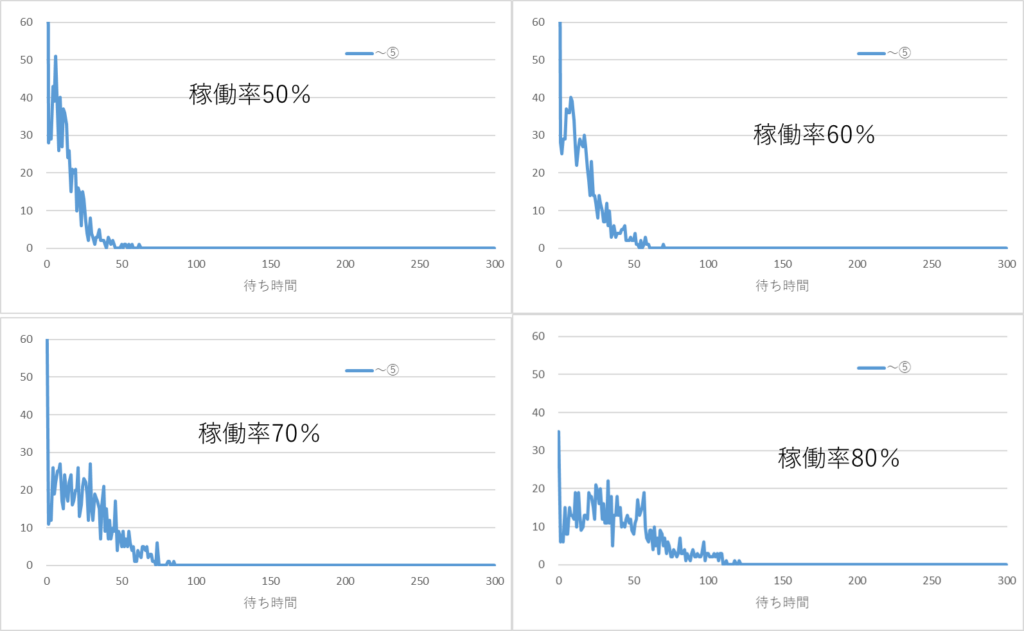
稼働率が高くなると待ち時間長くなりますが、その様子がわかります。平均待ち時間は稼働率が80%あたりから徐々に長くなり90%代に入ると急激に長くなります。平均値が長くなると同時にバラツキはダラダラと広がりが大きくなる分布となります。
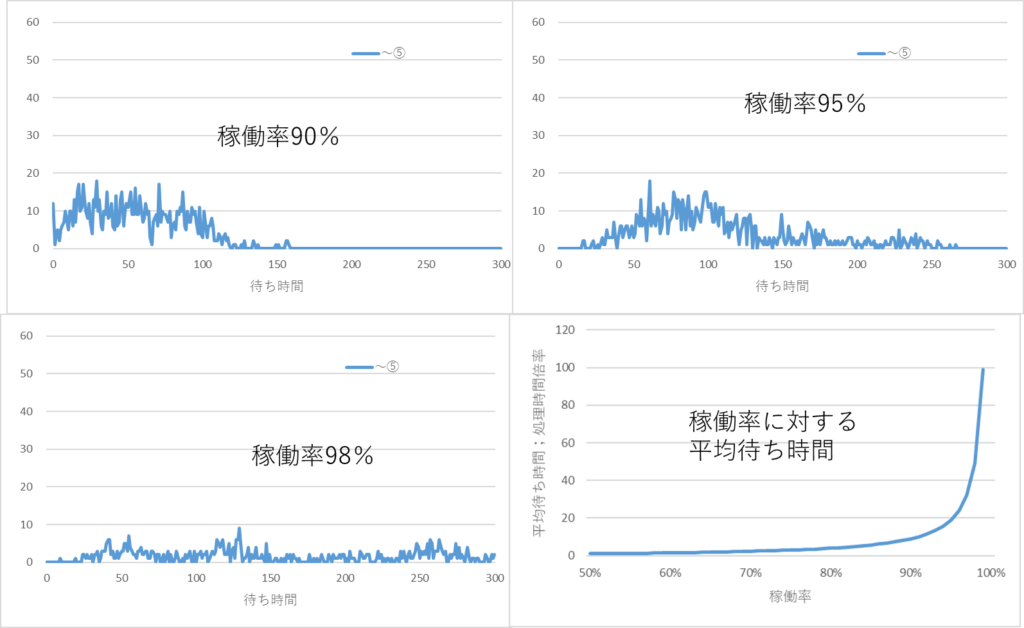
さらに厄介なことは、シミュレーションするごとに、分布形状が変化することです。稼働率90%の同一条件で4回シミュレーション行った結果を下図に示します。結果は省略しますが、稼働率が95%、98%と高くなると分布形状がますます不安定になります。
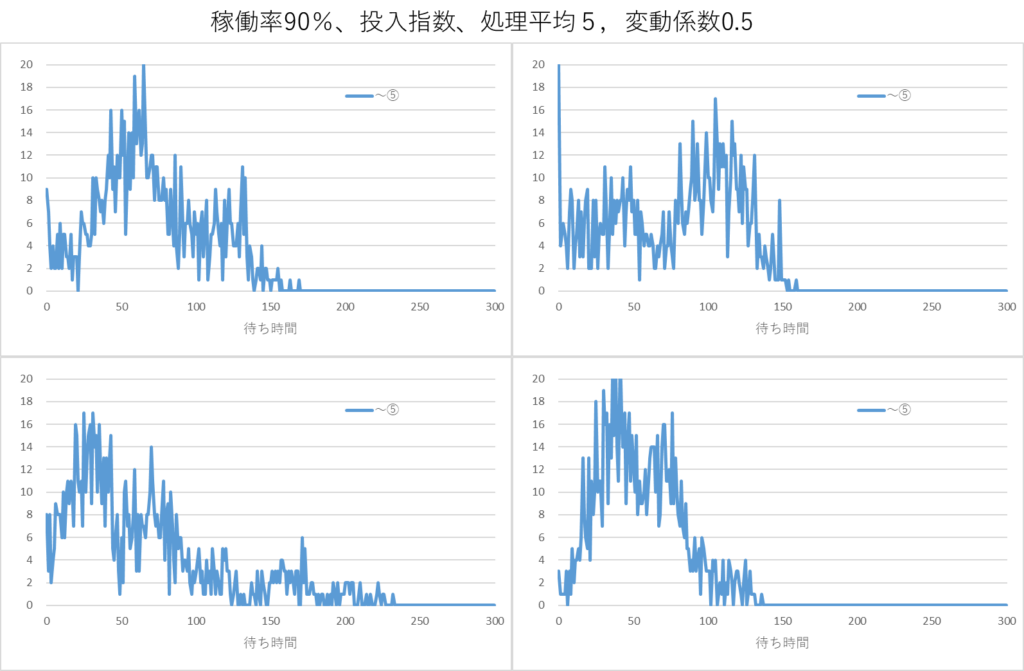
さらに、さらに、厄介なことは、稼働率を知ることが難しいことです。稼働率は観測時間が必要で、瞬間瞬間の稼働率はわかりません。生産ラインの稼働率なのか、あるいは工程ごとの稼働率なのか、も定義できません。
つまり、待ち時間のデータを採ったとしても、その時どのような稼働状態(稼働率)にあったのか知ることは困難だということです。稼働率によって待ち時間が大きく影響を受けることがわかっていても稼働率を合理的に定めることができません。70%~80%ぐらいだとか、いや90%だといった予測はできたとしても、今度は待ち時間の分布が安定しない、という問題に突き当たります。
待ち時間の平均値はある程度計算できますが、バラツキについては、分散も計算できなければ分布形状もわからない。これが待ち時間が持つ特徴です。
従って、待ち時間のデータをみて異常値だと判断する根拠がない、ということになります。処理時間の分布が、ほぼ正規分布に近似し、分散の加法性が成り立つのとは、まったく異なります。
ちょっと戻りますが、稼働率によって処理時間がどのような影響を受けるかのシミュレーション結果を下図に示します。稼働率が50%でも90%でも、あるいは105%でも、ほぼ同じであることがわかります。このような分布形状であれば、生産リードタイムの短縮活動に“異常値の発生原因をつぶす”というオーソドックスなアプローチが有効です。
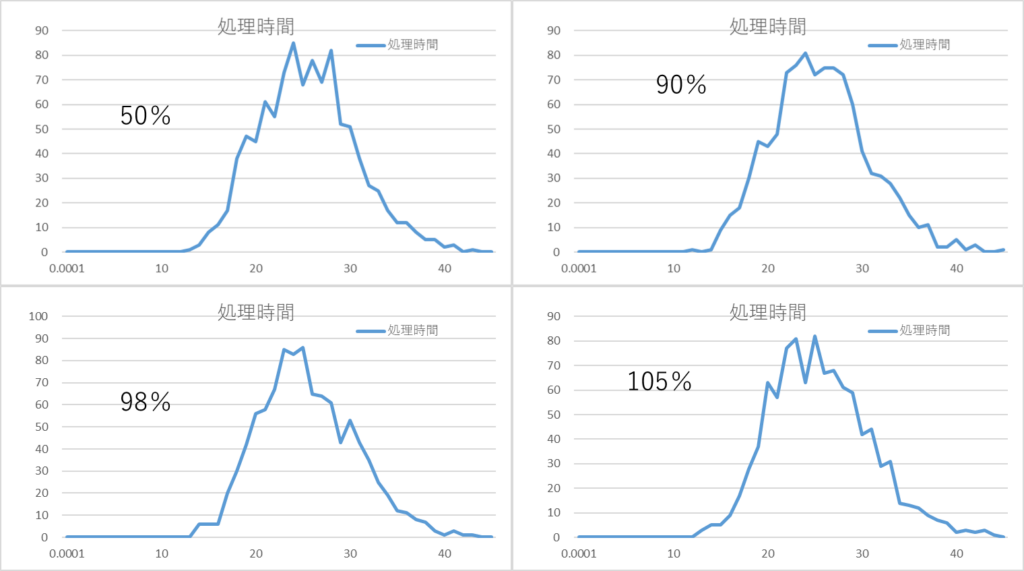
以下、貴殿のご説明、ご質問等(黒枠)についてコメントします。
私は論理解析をしているのではなく、改善コンサルを仕事にしていますのでそれを前提に質問してください。
まったく効果のない、的外れな改善方法をとっておられるので、お知らせしたいと思っておりました。貴殿のコンサルを受けた企業は理論に合わない改善方法を強いられたわけです。被害を受ける企業を増やしたくはありません。
80%が待ち時間が問題ではなくて、多くの会社のリードタイム分析結果をみるとリードタイムの80%程度が待ち時間となっているが、最大待ち時間の発生原因を分析しているところが少ないことを問題にしています。
最大待ち時間の発生原因の分析をしても論理的根拠が弱いので効果はあまりないと思います。中には、
「工程途中で半年以上止まっていたが、誰も気づかなかった。」
といったミスがあることは散見されることですが、そんな凡ミスがなくなったとしたら、待ち時間の問題は解決するんですか? リードタイムの80%も占める待ち時間の短縮が目的だったんではないですか?
人間のミスで発生した待ち時間(最大待ち時間)に匹敵する、あるいはそれを上回る待ち時間が原理的に発生し続けている中で「最大待ち時間の発生原因を分析」しても、あまり、というかほとんど意味がないと思いませんか。
なぜ最大待ち時間かというと、平均待ち時間は最大待ち時間の影響を受けるからです。最初にその影響を除去する必要があります。それが出来ていない会社が多いということと、最大待ち時間の発生要因を調べると工程待ちよりも人間の手続きミスや判断ミスが原因となっていることが多いという話です。
通常、山形の分布が多く、平均値付近のデータ数が多いため最大値の影響を受けにくいのですが、待ち時間の分布がダラダラと幅広く散らばっていると最大値の影響を受けやすくなります。待ち時間の特性を体感されているわけです。
「工程待ちよりも人間の手続きミスや判断ミスが原因となっていることが多い」を裏付けるデータって、取れるんですか。大きな遅れで検出可能なものはいくつかあるかもしれませんが、現場でよく起きるミスと最大待ち時間との関係は“わからない”んです。これが待ち時間の特徴のひとつです。
沖電線は平均値ではなく中央値で比較していますが、それでも当初の最大値の減少とともに中央値も減少していることがわかると思います。
最大待ち時間が平均待ち時間もしくは中央待ち時間の3から5倍以上の数字といった状況を異常値(異常滞留)と呼んでいます。沖電線でいえば当初の中央値が46日に対して、最大値は250日です。
3から5倍の根拠はありますか? 分布形状も不明、バラツキの程度(分散、標準偏差)もわからず。異常の判断基準は存在しませんので、意味のない決め事ですね。
佐々木さんは異常値を処理時間の何倍と定義していましたが、そんな定義はしていませんので訂正してください。
処理時間の代わりに待ち時間の平均値(中央値)を使うと、例えば処理時間が10分で待ち時間が60分、と、処理時間が60分で待ち時間が60分の区別がつかなくなります。平均待ち時間の式でお分りのように、待ち時間は処理時間に比例しますので、そのメカニズムを無視すると、分析がめちゃくちゃになります。待ち時間に言及するとき、処理時間を無視するような使い方をすることはありません。
最大値が排除出来て、待ち時間が平均値付近に集中してきたら次は工程負荷が待ち時間の発生要因になっていないかの検討をします。そこではじめて製造能力の問題がでてきますが、佐々木さんとその話をするつもりはありません。あくまでもここまでいくまでが大変だという話をしています。
到着間隔と処理時間の平均とバラツキで決まる待ち時間ですので、貴殿の言う異常値をなくしても、異常値に匹敵するあるいは異常値以上の待ち時間が発生し続けることになります。待ち時間は「平均値付近に集中する」ことは原理的にありません。シミュレーション結果を見てもわかる通り、待ち時間は平均値が下がるとともにバラツキも小さくなります。「最大値を排除したら今度は工程負荷・・・」という手順は待ち時間の特性からみて、機能しないことは明らかです。
そもそもこの間村上さんたちといった上場会社など、今までデータを取ることさえしていなかったのでどうやってデータを釣るかからの検討が必要だとのことでした。
今の100倍も、1000倍ものデータをオンラインでとることができるのならば、何らかの解決策につながるかもしれません。現実的は待ち時間のメカニズムの解析が壁にぶつかっている状態ですから、小手先でデータを採ってもなんの役にも立たないと思います。
コンサルの最初の手順として最大値(異常滞留)の発生原因を分析してつぶしておく必要があるという話をしています。業務改善コンサルなら当たり前のアプローチだと思いますが、なぜ佐々木さんがこの問題を軽視するのかよくわかりません。佐々木さんはコンサルをめざしているのではないのですか?
処理時間の異常値の発生原因ならつぶせますが、待ち時間の場合、異常値の判断基準もなく、異常値に匹敵する、あるいはそれ以上長い待ち時間が発生し続けていること、またその発生状況を推定することは難しい、、、などの理由でできないんです。軽視しているのではなくて、従来、無意識のうちに取ってきた異常発生原因の分析というアプローチは待ち時間の分析には機能しないと申し上げているわけです
私は学者ではありませんので待ち時間の数値シミュレーションをしているわけではありません。コンサルとしてこの過程は無視してもいいとでもいわれるのでしょうか?それだと業務改善コンサルはできません。
理に合わない方法で改善しようとしていることに警告を鳴らしているところです。貴殿のコンサルを受けた企業で、待ち時間に関する業務改善に限っていえば、効果が出ることはほんどないことは明らかです。コンサルを受けた企業に何ら利益をもたらすことなく、むしろ混乱だけが残った、という状況ではないでしょうか。
コンサルとして、より有効な改善サービスをするためには、生産ラインの基本メカニズムをきちんと理解しておく必要があります。決して高度な理論ではありません。突き詰めて言えば、「待ち時間の分布って、よく分かっていないんだ」ということを知っていれば、それをベースにする“異常値”の検出はできない、ということぐらいは予感できるのではないでしょうか。この辺りについては、欧米の方が一歩か二歩進んでいるように思います。
少し話は飛びますが、生産スケジューラの問題もこの待ち時間が直接の原因となっております。スケジューリングではどうしても高い稼働率を狙います。そうすると、シミュレーション結果でも示したように、捕まえようのない広がりで待ち時間が発生します。その時間は処理時間の数倍、数十倍の長さですから、予定した時間とはかけ離れた時間で工程を流れることになり、実行不可能となるわけです。
2000年代、生産スケジューラメーカが10社ぐらいあったでしょうか。米国での話です。DBR(ドラムバッファーロープ)スケジューリングができるというふれこみで元気でした。ところが2000代後半にはほとんどのスケジューラメーカは姿を消しました。ボトルネックだけをスケジューリングすればOK、のはずでしたが、ボトルネックの稼働率を100%にすると実行可能なスケジューリングできないことがわかってきたからです。原因は待ち時間の発生です。待ち時間の発生を考慮に入れたスケジューリングはできませんでした。
待ち時間理論ことは知っています。昔音声通信ネットワークの設計をしていましたので、その時にアラーンの法則を使っていました。懐かしい思い出です。
待ち行列理論に詳しい方をご存知でしたら、待ち時間の分布やバラツキ(分散、標準偏差)の計算などについて聞いてみてください。何かしらの改善のヒントが得られるかもしれません。
佐々木俊雄
2021/11/22