
生産型の流れでは、工程ひとつひとつが待ち行列現象を起こす形をしています。生産にたずさわる誰もが、工程の稼働率をできるだけ高く維持しようとします。そうすると、待ち行列現象が強くなり、長い待ち時間が発生することになります。
プロジェクト型でも待ち行列現象は起きますが、部分的であり、その影響は生産型に比べれば軽微です。
待ち行列現象の待ち時間とはどんな特徴があるんでしょうか。事例で試算してみましょう。図1をご覧ください。できるだけ同じ条件で比べた方がわかりやすいと思います。生産型もプロジェクト型も直列5工程(5タスク)、処理時間平均は工程4(タスク4)が9時間、他の工程(タスク)は7時間です。生産型の工程バラツキは変動係数0.25、プロジェクト型は0.75と大きくしてあります。生産型のオーダはランダムに投入されますが、平均時間間隔は10時間です。プロジェクト型はプロジェクトX、ひとつです。
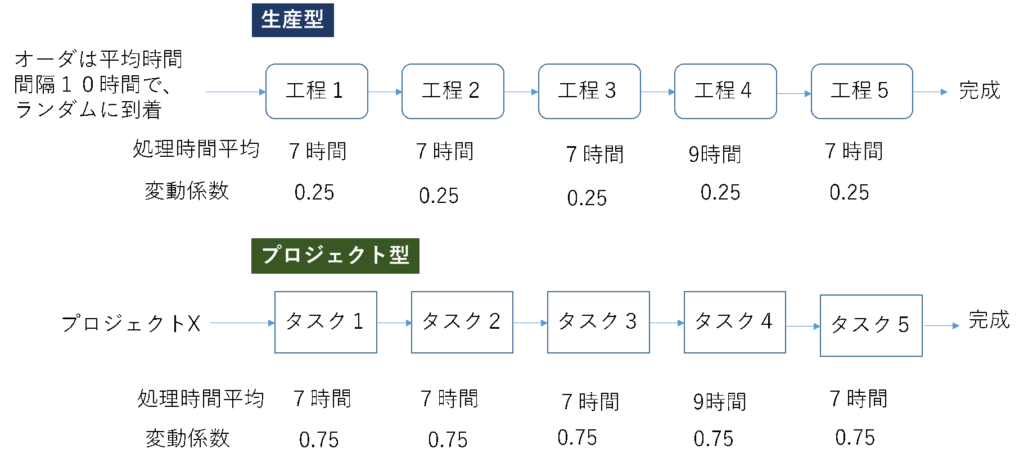
図1 事例研究;生産型とプロジェクト型の比較
生産型では、ひとつのオーダが完成するまでの時間、プロジェクト型ではプロジェクト開始から完成までの時間を試算してみます。その一例を図2に示します。プロジェクト型のタスクのバラツキは生産型のそれの3倍であることにご留意ください。にもかかわらず生産型の所要時間の方が平均も最大値も長くなっています。分布をみても、プロジェクト型は、正規分布に近い分布形状ですが、生産型のそれは右に大きくすそ野が伸びています。
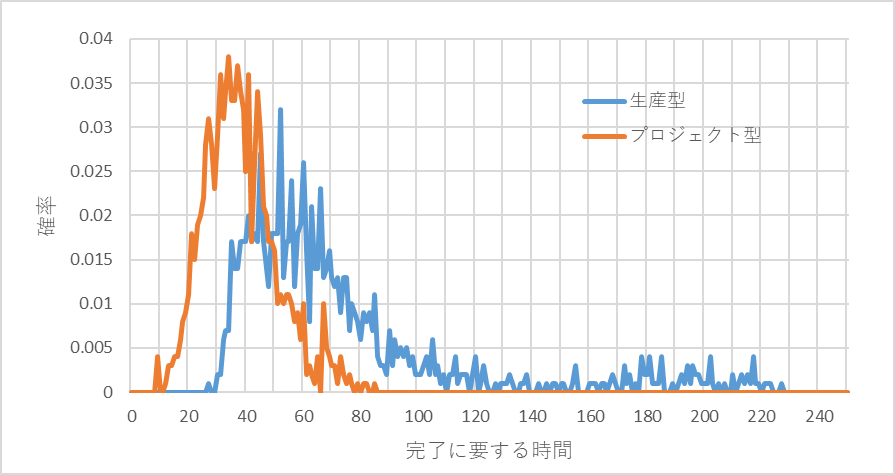
図2 生産型とプロジェクト型の完成までの所要時間の比較
どの工程での待ち時間が長いのか、調べてみました。工程1,2,3、と5はほぼ同じなので、工程1を代表に、工程4の待ち時間と比べてみました。結果を図3に示します。工程4の待ち時間が全体の所要時間に大きく影響を与えていることがわかります。
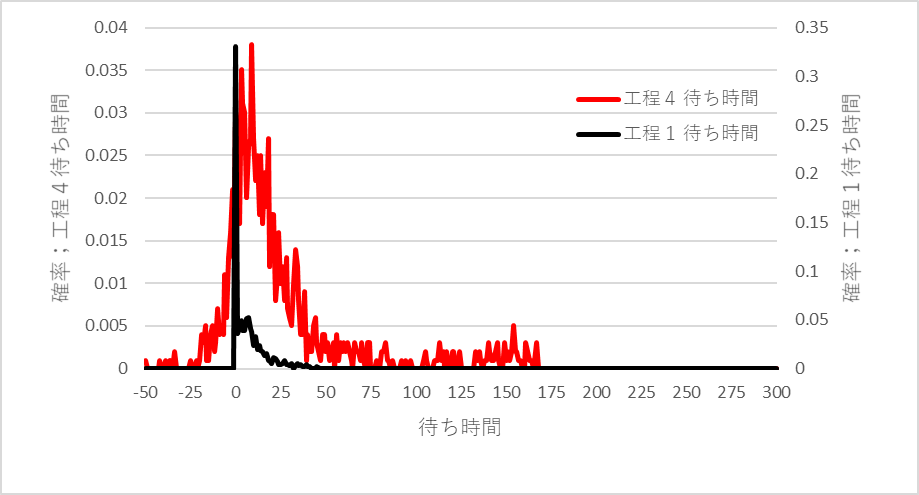
図3 工程4の待ち時間が長い
工程1,2,3,5の稼働率は0.7、工程4のそれは0.9。稼働率が高くなると、待ち時間が急激に長くなる待ち行列現象の影響であることは明白です。
この待ち行列現象による待ち時間。困ったことに、実に、捉えにくいというか、扱いにくいというか、始末に負えないんです。図2と図3のデータを採るとき、計算ごとに結果が結構バラツクんです。乱数を使っていますので、バラツクのは当たり前なんですが、計算するごとに出る結果の違いに驚いてしまいます。お示しした結果は、だいたい平均的なものです。
プロジェクト型の所要時間の分布はだいたい正規分布に近いのですが、生産型のそれは右に長々とすそ野を引くのが特徴のひとつです。プロジェクト型の分布は統計理論を応用できそうですが、生産型の分布は統計理論では扱えそうにありません。生産型の分布を扱える数理モデルってあるんでしょうか。いろいろ探してみたんですが、見つかりません。
待ち行列理論も調べてみました。待ち行列理論の数理モデルは待ち時間、待ち行列の長さ、待っているWIPの数を計算できますが、すべて平均なんです。生産管理では、平均値も有用な情報ですが、分布の端っこの部分が重要ですので、そこを知りたいんです。確率分布の形状を扱える数理モデルって、ないのかなぁ~、、。今のところ、見つかっておりません。ご存知の方がいらっしゃいましたら、ぜひ、ご一報ください。
プロジェクト型のスケジューラでは、バラツキを考慮したものがあります。プリミティブなものでは、3点見積で標準偏差を求め、本格的なものは過去の蓄積されたデータから標準偏差を求め、加法性を利用して、各タスクの平均、分散を合算してプロジェクト全体の所要時間を算出する。正規分布で近似して、納期の達成確率などを見積もるようなことが行われているようです。
では、生産スケジューラではどうなんでしょうか。待ち行列現象を考慮した生産スケジューラって、市販されているのでしょうか。
生産スケジューラ・ベンダーの宣伝文句をみると、受注生産、多品種少量・変量、即座の計画変更、、なんでもゴザレ、、という感じですが。額面通り受け取れば、当然のことながら、待ち行列現象に対しても、対応策をとっているのではないか、と思われるんですが。実態はどうなんでしょうか。
さらに、追求してみたいと思います。